Содержание урока по Qlik Sense
Что такое ETL & ELT? В чем отличие? Как та или иная технология может быть применима в Qlik Sense
Извлечение, загрузка и преобразование (ELT) — это процесс, с помощью которого данные извлекаются из исходной системы, загружаются в хранилище данных, а затем преобразовываются.
E, T, L:
- Extraction (Извлечение): извлечение необработанных данных из неструктурированного пула данных и их перенос во временное, промежуточное хранилище данных.
- Преобразование (Transformation): структурирование, обогащение и преобразование необработанных данных в соответствии с целевым источником.
- Загрузка (Loading): загрузка структурированных данных в хранилище данных для анализа и использования инструментами бизнес-аналитики (BI).
ETL требует управления необработанными данными, включая извлечение необходимой информации и проведение правильных преобразований, чтобы в конечном итоге удовлетворить потребности бизнеса. Каждый этап – извлечение, преобразование и загрузка – требует взаимодействия инженеров и разработчиков данных, а также работы с ограничениями емкости традиционных хранилищ данных. Используя ETL, аналитики и другие пользователи BI привыкли ждать , поскольку простой доступ к информации недоступен до тех пор, пока не будет завершен весь процесс ETL.

Извлечение, загрузка и преобразование (ELT) — это процесс, с помощью которого данные извлекаются из исходной системы, загружаются в хранилище данных, а затем преобразовываются.

QVD файлы
Qlik Sense имеет собственный формат хранения данных. Данные из разных систем выгружаются и сохраняются в QVD-формате. Этот формат файлов очень быстро загружается в Qlik Sense для дальнейшей обработки. Это как dump базы данных. Выгрузка и загрузка миллионов строк (без доп.условий) занимает секунды.
Иногда можно построить серьезные коммерческие проекты только на QVD файлах.
- Первый уровень данных — сырые данные (выгрузки из источников без каких либо изменений).
- Второй уровень — обработанные файлы (объединение данных, дополнительные аналитики, флаги, специальные поля, рассчитанные меры и т.д.).
- Третий уровень — агрегированные данные и т.д.
Эти файлы можно использовать в разных приложениях, за них могут отвечать разные сотрудники и сервисы. Скорость загрузки из таких файлов в десять раз быстрее чем из обычных источников данных. Это позволяет экономить на базе данных и обмениваться информацией между различными приложениями Qlik.
Пример организации ETL-процесса на примере QlikView (в Qlik Sense аналогичные процессы):

Организация ETL на базе Qlik Sense – Вариант 1
- Этап выгрузки данных из систем (Extract): На Qlik Sense формируются процедуры выгрузки данных без изменений (как есть). В рамках инкрементальной загрузки рекомендуется выгружать только новые и/или изменившиеся данные. Для выгрузки каждой отдельной таблицы пишется отдельный скрипт, который вызывается в Qlik Sense через must_include. Схема следующая:
- Загружаем данные из таблицы базы данных (или другого источника)
- Сохраняем загруженную таблицу в QVD-файл
- Удаляем таблицу
- Переходим к следующей таблице и т.д.
- Этап трансформации данных (Transformation): На этом этапе из сырых данных формируются справочники, которые затем будут использоваться в моделях. На этом этапе подтягиваются различные параметры из смежных справочниках (например, для товаров можно подтянуть атрибуты, разные свойства, нормативы из других справочников). На этом этапе формируются QVD файлы, которые будут использоваться в разных приложениях и дальнейших ETL-процессах. Убираются ненужные атрибуты, производится очистка параметров. На этом этапе рекомендуется использовать вместо join функцию mapping & applymap. Если данные приходят из разных филиалов, То на этапе трансформации они по прежнему собираются в рамках отдельного филиала. Это необходимо, чтобы минимизировать затраты на ресурсы при обработке данных (распараллеливание процессов обработки, облегчения поиска ошибок, облегчение процесса тестирования/разработки.
- Этап агрегации данных (как часть процесса Transformation): Этот этап является дополнительным этапом, который по сути входит в шаг трансформации данных. На этом этапе собираются специфические таблицы (файлы QVD) для конкретных моделей. При этом данные очень часто группируются, чтобы уменьшить размер таблиц. Т.е. фактически это этап агрегации/консолидации данных. Данные из различных филиалов собираются в один единый файл.
Краткая классическая схема ETL-процесса (процесса выгрузки, обработки данных)
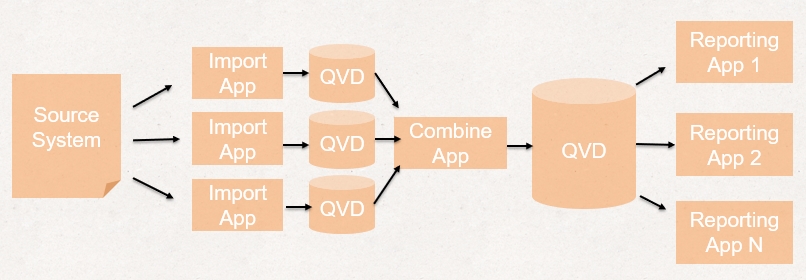
Общая схема ETL-процесса в Qlik Sense
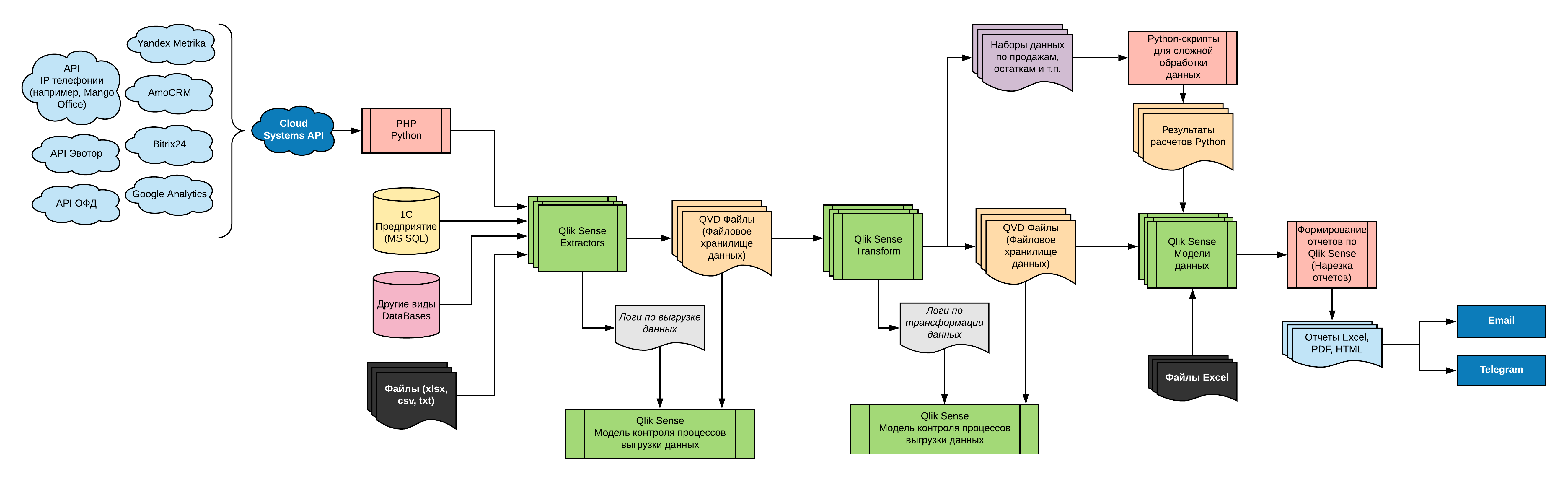
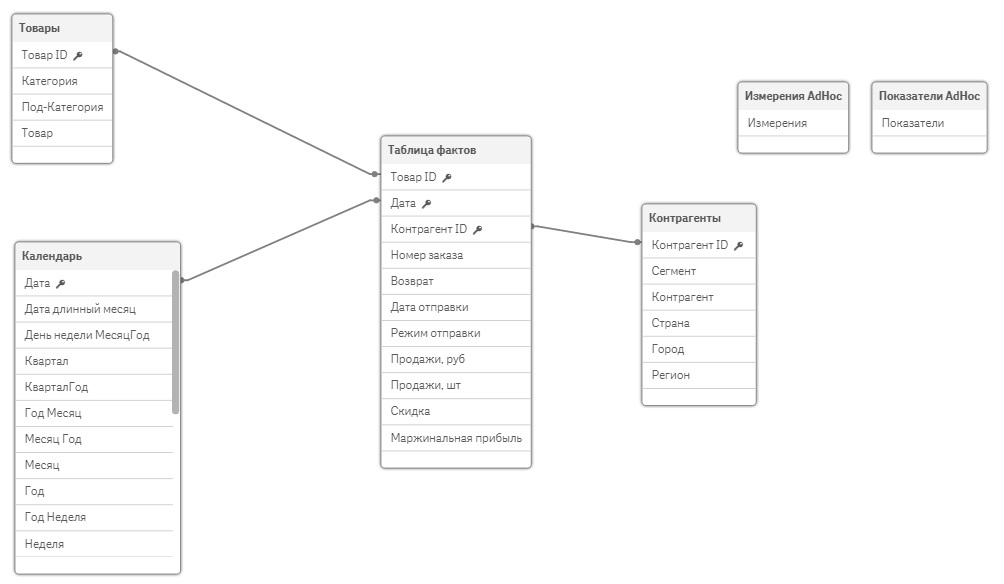
На завершающем этапе ETL-процесса данные загружаются в приложение (создается модель данных). Есть различные схемы моделей данных, целевая схема – звезда:
- Таблица фактов (продажи в разрезе клиентов, товаров, по датам)
- Справочники (Измерения): Товары, Клиенты, Календарь
- Вспомогательные таблицы, не связанные с другими таблицами: Data Islands
Пример модели данных:
TSEEQ: The Structured ETL Engine for Qlik Sense
TSEEQ – это структурированный движок ETL для Qlik, может быть полезен для вашего проекта. TSEEQ – это механизм ETL, а не процесс; TSEEQ можно использовать для оптимизации любого ETL-процесса, который вы используете в своей реализации Qlik Sense.
Основы проектирования хранилища данных для Qlik Sense
Хранилище данных (в формате QVD-файлов) и Bus Matrix
Хранилище данных Qlik Sense предпочтительно должно соответствовать корпоративной архитектуре данных со стандартными фактами и измерениями, которые могут совместно использоваться в разных моделях. Несмотря на то, что qvd-файлы используются в Qlik Sense, необходимо соблюдать существующие определения данных и управление ими. Любые новые факты, измерения и меры, разработанные с помощью Qlik Sense, должны дополнять архитектуру компании.
1. Создание Bus Matrix хранилища данных:
- Матрица бизнес-процессов (фактов) и стандартных измерений является основным инструментом для проектирования и управления моделями данных и передачи общей архитектуры BI.

- В этом примере бизнес-процессами, выбранными для модели, являются Продажи через интернет, продажи через посредников и главная книга.
2. Создание Bus Matrix:
- Результат процесса проектирования модели должен включать более подробную Bus Matrix.

- Bus Matrix: интернет-продажи, продажи через посредников и главная книга
- Ясность и согласованность содержания таблиц фактов, определений основных показателей и всех измерений дает уверенность при переходе в фазу разработки.
Extract Level: Описание основных элементов скрипта загрузки данных в Qlik Sense
Создание подключения в скрипте Qlik Sense
Для загрузки данных из разных источников совершенно необязательно знать синтаксис и команды Qlik Sense. На первоначальном этапе работы достаточно просто пользоваться мастером генерации скрипта.
Для этого в приложении заходим в редактор скрипта:

Справа нажимаем “Создать новое подключение”:
У Qlik Sense есть различные коннекторы к различным источникам данных. В рамках этого раздела мы создадим только коннектор к директории на диске (где лежат QVD-файлы):

Указываем директорию и название соединения:
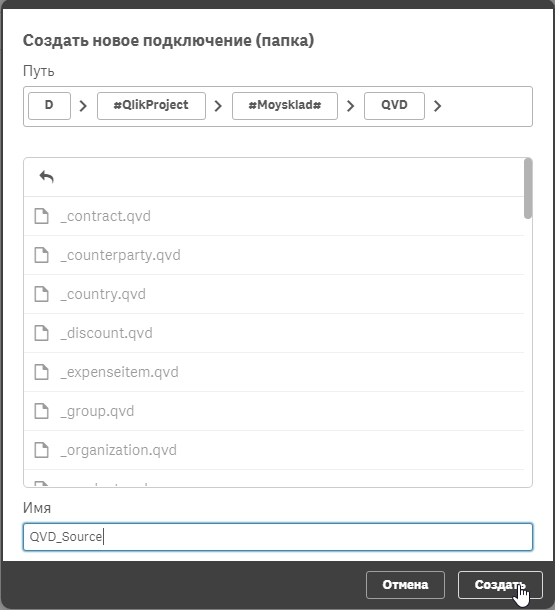
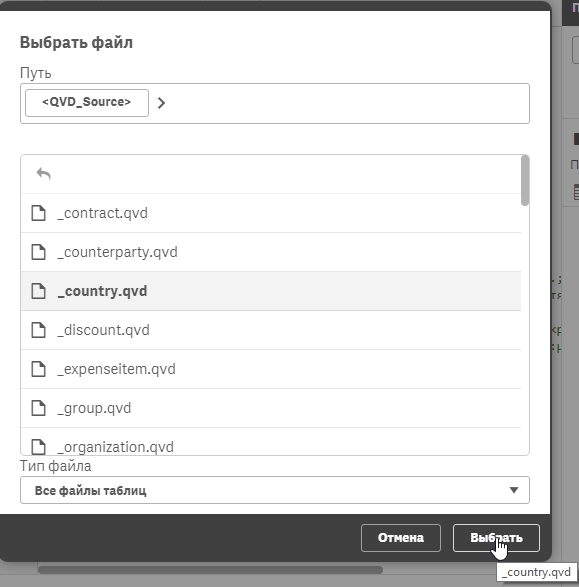
Далее в соединении нажимаем на кнопку “Выбрать данные”:

Qlik Sense предложит список файлов для выбора из директории (можно провалиться в поддиректорию/подпапку):
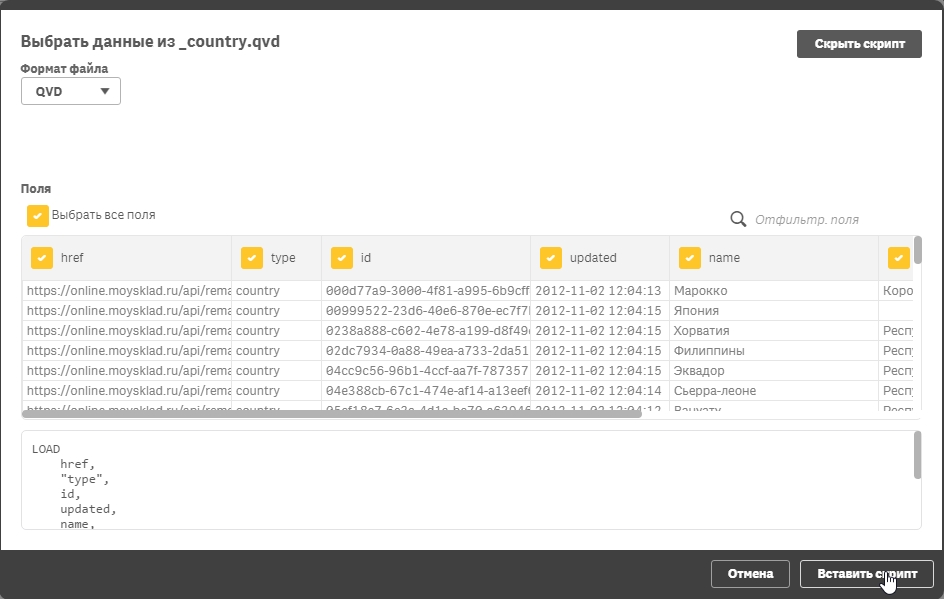
В окне предпросмотра выбираете колонки, которые необходимо загрузить из файла (либо генерируете скрипт и в скрипте удаляете ненужные колонки):
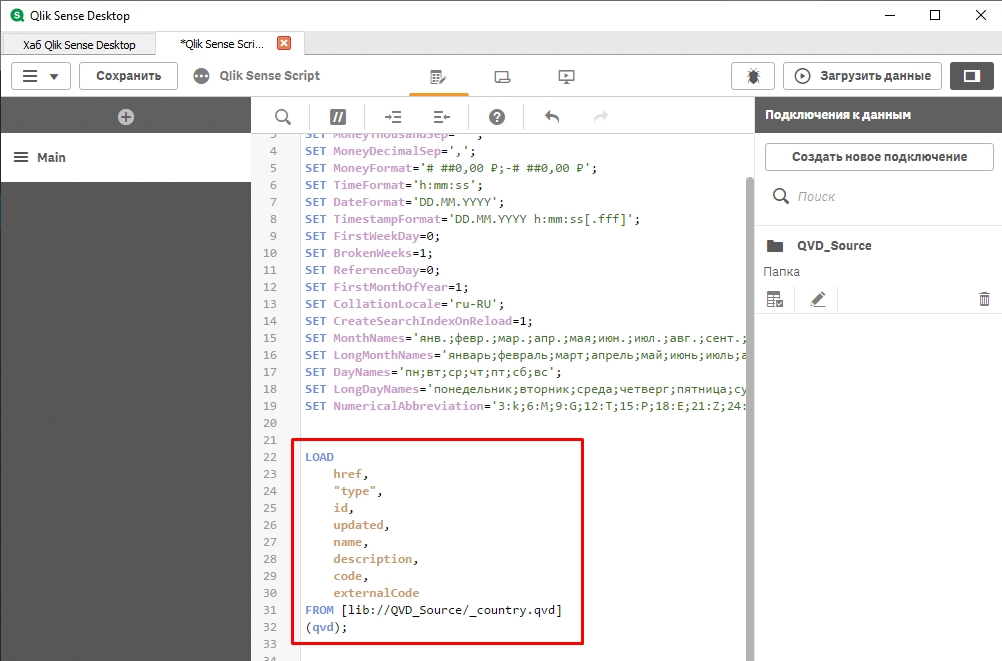
Мы получили сгенерированный скрипт загрузки данных из QVD-файла. Такая цепочка действий выполняется практически для всех источников данных (включая базы данных). Единственное исключение, наверное, это получение данных из API. Но это уже продвинутая разработка, на первом этапе это не потребуется.
Операторы загрузки данных LOAD QVD & SQL SELECT
Для загрузки данных из QVD файлов используется структура:
Контрагенты:
LOAD
"Контрагент ID",
Сегмент,
Контрагент,
Страна,
Город,
Регион
FROM [lib://Источник данных/Контрагенты.qvd] (qvd);
Для выгрузки данных из базы данных необходимо создать подключение к БД и сформировать скрипт загрузки. Скрипт загрузки может быть составлен несколькими вариантами. Пока что рассмотрим три варианта без подробного разбора.
Вариант 1:
LIB CONNECT TO 'MySQL_Enterprise_Edition';
[mysql_table_name]:
SELECT `option_id`,
`option_name`,
`option_value`,
autoload
FROM `database_name`.`mysql_table_name`;
Вариант 2:
LIB CONNECT TO 'MySQL_Enterprise_Edition';
[mysql_table_name]:
LOAD option_id,
option_name,
option_value,
autoload;
SELECT `option_id`,
`option_name`,
`option_value`,
autoload
FROM `database_name`.`mysql_table_name`;
Вариант 3:
LIB CONNECT TO 'MySQL_Enterprise_Edition';
[mysql_table_name]:
SQL
SELECT `option_id`,
`option_name`,
`option_value`,
autoload
FROM `database_name`.`mysql_table_name`;
Загрузка данных из Excel – LOAD FROM XLSX
[Планирование ден.потоков]:
LOAD
"Доходы и расходы",
"Варианты расходов",
"1 месяц",
"2 месяц",
"3 месяц",
"4 месяц",
"5 месяц",
"6 месяц",
"7 месяц",
"8 месяц",
"9 месяц",
"10 месяц",
"11 месяц",
"12 месяц"
FROM [lib://XLSX_DataSource/1_Analiz_denezhnykh_potokov.xlsx]
(ooxml, embedded labels, header is 2 lines, table is [Планирование ден.потоков]);
Пример загрузки данных из CSV – LOAD FROM CSV
[Продажи]:
LOAD
SKU,
"Group",
"Week",
Store_id,
"Sales qty, pcs.",
"Sales, RUB",
"Sales in the cost, RUB",
"Promo index",
Availability
FROM [lib://CSV_Source/Test.csv]
(txt, codepage is 1251, embedded labels, delimiter is ';', msq);
Создание таблицы в скрипте – хранимая таблица в скрипте – LOAD * Inline []
Иногда в ходе загрузки данных требуется создать таблицу со значениями в скрипте. Например, для фильтров. Не всегда хочется генерить дополнительный файл XLSX, проще и быстрее сделать все в скрипте. Для этого есть конструкция LOAD * Inline:
[Таблица хранимая в скрипте]:
LOAD * Inline [
Поле 1, Поле 2, Поле 3
Значение 1.1, Значение 2.1, Значение 3.1
Значение 1.2, Значение 2.2, Значение 3.2
Значение 1.3, Значение 2.3, Значение 3.3
];
Сохранение таблицы в QVD-файл
STORE [Регистр Продаж] into 'lib://ExtractData/1С_Предприятие/РегистрПродаж.qvd' (qvd);
…
Продолжение следует
Transform Level: Описание функций, приемов эффективного преобразования данных
В этом разделе я опишу основные приемы обработки данных в скрипте Qlik Sense. Конечно же в одной статье нереально вместить и описать все случаи и все подходы по обработке данных. Основная цель этого раздела – заложить базис синтаксиса, основных конструкций по обработки данных в скрипте Qlik Sense.
Rename Table / Rename Field / Drop Table(s) / Drop Field(s)
todo
Load * Resident
todo
Загрузка данных по маске From ‘FileName_*.qvd’ (qvd)
todo
Concatenate & NoConcatenate
todo
AutoGenerate
todo
Exists()
todo
SubField()
todo
Match() & WildMatch()
todo
Mapping / ApplyMap
todo
Left Join & Inner Join
todo
For i To NoOfRows / NoOfFields. Peek() & FieldName()
todo
Load While IterNo()
todo
if(). Комбинация Pick() & Match() в скрипте
todo
Агрегация данных Group By. Предрасчет показателей в скрипте
todo
…
Продолжение следует
Load Level: Загружаем данные в модель. Основные концепции и подходы по созданию моделей
…
Продолжение следует
Краткий инструктаж по написанию скриптов загрузки
В этом разделе будут описаны некие принципы для организации ETL-процесса с помощью Qlik Sense (без использования других инструментов обработки данных).
1. В операциях Concatenate, Join не используйте Distinct. Если таблица формируется с помощью последовательных операций объединения данных в одну таблицу с помощью оператора принудительного объединения таблиц Concatenate (сходных по набору столбцов, но имеющих несколько разных колонок), операторов присоединения данных Join (Left, Right, Inner) – не используйте Distinct – иначе Вы потеряете одинаковые строки (это не дубликаты, просто в 1 документе могут быть указан один и тот же товар двумя строками, если в системе учета это не запрещено). Причем не важно, на каком шаге был применен Distinct (в самом начале обработки данных или в конце).
2. Используйте меппинги ApplyMap вместо Join. При большом объеме данных это ускоряет загрузку данных.
3. Одинаковые части формул рекомендуется выносить в переменные, чтобы упростить дальнейшую поддержку кода приложения. Переменные можно вести как в Excel, так и в Variable Manager. Также можно использовать различные расширения или extension (например, Qlik Sense Variable Editor Mashup).
4. Ключи оборачивать в TEXT(), даже если это hash-ключ из 1С Предприятие 8.3. Qlik имеет неприятную штуку с изменением ключей (встречается редко, но проскакивает). В обычных ключах очень часто клик может преобразовать запись “130E0” в “13E1”. Т.е. знак “E” он воспринимает как разряд.
5. Для генерации составных ключей вместо hash128() рекомендуется использовать autonumberhash128() – он быстрее. Генерация ключей с помощью функций Hash128 и Hash256 утяжеляет модель, что ведет к увеличению использования RAM.
6. Preceding Load: Для того, чтобы сократить объем кода и оптимизировать скорость загрузки данных рекомендую использовать Preceding Load (Предшествующий оператор LOAD). Preceding Load можно использовать и при загрузке из файлов, из баз данных, из уже загруженных таблиц с помощью оператора Resident. Количество “этажей” Preceding Load не ограничивается (используйте в меру разумного).
SimplePreceding:
LOAD
*,
[To Date] - [From Data] as Duration
;
LOAD
Date(Date#(FromDate, 'YYYYMMDD'), 'DD MMM YYYY') as [From Date],
Date(Date#(ToDate, 'YYYYMMDD'), 'DD MMM YYYY') as [To Date],
FROM [lib://SourceData/Durations.xlsx] (ooxml, embedded labels, table is Data);
7. Нумерация строк в большой таблице фактов. Если нужно пронумеровать таблицу фактов, которая грузится из нескольких источников, то для начала загружаем все факты в 1 таблицу Qlik Sense, затем перекладываем таблицу саму себя (Load * Resident) с функцией RecNo().
RowNo() для больших таблиц не нужно использовать, т.к. она очень медленно работает.
8. Не создавайте меппинги напрямую из больших QVD файлов. Сначала грузим QVD в таблицу, затем перекладываем с помощью Resident данные в Mapping таблицу. Загрузка данных в Mapping таблицу отключает оптимизированную загрузку данных.
9. Избегайте сложных динамически генерируемых полей, таблиц, кусков кода. Любая динамика усложняет поддержку решения. Особенно это критично, когда один разработчик уходит из команды, код приходится изучать с нуля. Если другого выхода нет, кроме как использование динамики, то делайте генерацию кода, полей и т.п. Если есть простой способ написания кода – используйте его. Унификация и простота – залог облегчения поддержки инфраструктуры, etl-процесса. Не гонитесь за интересными решениями, прокачкой ИТ-навыков – это вредит ИТ-решениям компании (но разработчикам конечно это на пользу). Плюс повышаются косвенные затраты компании, в какой-то момент потребуется вместо 1 разработчика на поддержку использовать 2х разработчиков.
…
Продолжение следует



{kind=link}
Эх, оглавление есть, а содержание ещё не дописал автор: Transform Level: Описание функций, приемов эффективного преобразования данных